
[Los
siguientes comentarios no constituyen una réplica directa a la
reseña de Roberto Colom, y tampoco se centran en el libro revisado. Recogen
mi visión sobre las presentaciones de James R. Flynn durante las pasadas
décadas].
Las
ganancias en las puntuaciones de los test de CI se conocen desde hace 70 años y
han preocupado a los investigadores de la inteligencia, en parte porque los
test de CI, como instrumentos, han sido inestables, y en parte porque la causa
(o causas) de esa inestabilidad se ha mostrado escurridiza.
Cuando se
observó por primera vez el efecto (en los años 40) la tendencia era positiva, y,
por tanto, sugería mejoras en algún factor ambiental. En aquel momento, las ganancias
se atribuyeron a la mejora educativa, tanto en cantidad como en calidad.
Ciertamente, los datos apoyaban esa conclusión, al menos en aquella época.
En la
década de los 80, Richard Lynn y James Flynn publicaron artículos que
reavivaron el interés por el aumento de las puntuaciones. Siguió un enorme
número de artículos. Una tendencia que se mantiene todavía.
Un tema
común a la mayoría de los artículos sobre el Efecto Flynn (Flynn Effect)
es que cada autor expone una explicación causal posible y argumenta que esa
causa es la ÚNICA capaz de explicar el aumento secular de las puntuaciones. Al
estudiar cada una de las bases de datos, se observa que se muestran ganancias
con características diferenciales a las observadas en otras bases de datos. Por
ejemplo, algunos datos muestran altas ganancias en un país, otros datos
muestras ganancias bajas y otros no muestran ninguna ganancia. En algunos
casos, las ganancias parecen mayores en individuos brillantes, en otros
estudios se observa lo contrario y en otros las ganancias son uniformes.
Algunas bases de datos muestran distintos grados, e incluso distinta dirección,
en la misma localización geográfica, según los años considerados. Por ejemplo, según
Teasdale & Owen:
“…las ganancias son
de 3 puntos para las décadas 1959-1969 y 1969-1979, y en la década 1979-1989 la
ganancia es de 2 puntos. Desde 1989 a 1998 la ganancia ha sido solo de 1.3
puntos y desde aquí la ganancia se detiene en 2000 y no ha vuelto a recuperarse”.
La
dirección se invierte; otros países siguen la misma trayectoria.

Flynn ha
sido especialmente productivo durante las décadas en las que la ciencia se ha
interesado por las ganancias seculares. Ha discutido con Jensen y Lynn
produciendo una mezcla de razonamientos fuertes y débiles sobre las causas de
las ganancias. En su evaluación inicial de las ganancias, Flynn señaló que si
fuesen “reales”,
sus consecuencias en la vida cotidiana debían ser evidentes y abundantes.
Comparó numéricamente generaciones actuales y anteriores, mostrando que las
diferencias en las puntuaciones eran de tal magnitud que las generaciones
pasadas tendrían que haber sido incapaces de completar tareas que nosotros
consideramos simples. Estaba en lo correcto al hacer esta observación. Pero,
con el paso de los años, Flynn comenzó a argumentar que los cambios en las
puntuaciones debían reflejar cambios en la vida cotidiana (factores
socio-ambientales) y, por tanto, debían ser significativos. Fue muy cauto al
elegir las palabras.
En 2007
conocí a Flynn y comprobé que era alguien cálido y que le atraían los
comentarios y las preguntas. Le pregunté si pensaba que las ganancias seculares
se podían atribuir a g. Respondió con
su ejemplo favorito de ítem de un test en el que se preguntaba por la relación
de los perros y los conejos (la declaración es que el niño moderno identifica
inmediatamente a ambos como mamíferos, mientras que las generaciones previas no
lo hacen) y siguió con su noción “histórica” sobre que la importancia de los ítems
varía en función de los cambios en la sociedad. Seguidamente (con respecto a la
pregunta inicial sobre g) se limitó a
contestar: “No
lo sé”. Fue una respuesta razonable que no exigía ninguna defensa.
La
discusión de este post implica una
serie de aspectos sobre los argumentos presentados por Flynn, quien ha
considerado la mayor parte de las contribuciones intentando eliminar o
minimizar la mayor parte de las causas que se han propuesto. La dificultad con
algunos de estos rechazos reside en el enorme rango de la formas que adopta el
efecto en distintas bases de datos (como dije anteriormente). Aunque está de
acuerdo en que hay muchas causas, realmente no ha aceptado esa idea y se ha
dedicado a discutir los cambios en la sociedad como responsables del
funcionamiento diferencial de los ítems en distintas generaciones. Este hecho obliga
a traducir los comentarios de Flynn desde su estilo a las convenciones que se
usan regularmente en los artículos de investigación. Por ejemplo, los cambios
generacionales en la sociedad que él describe parecen corresponder,
precisamente, a lo que nosotros entendemos por “invarianza” o “funcionamiento diferencial de los ítems”.
Él simplemente opta por usar una descripción de lo que otros han considerado
como un fracaso al confirmar la invarianza o al encontrar ausencia de
invarianza (es decir, que el test funciona de modo diferente en distintas
cohortes o generaciones).
Otro ejemplo: Flynn ha discutido extensamente que las ganancias no pueden atribuirse a g, como ha mostrado la mayor parte de la investigación sobre este aspecto de la inestabilidad de la puntuación [son muy escasos los resultados que han ido en la misma dirección. Para un ejemplo de resultado opuesto véase Colom, Juan-Espinosa, García, 2001. The secular increase in test scores is a 'Jensen effect’. Personality and Individual Differences, 30, 553-559]. Flynn ha optado por ignorar la posibilidad de que la varianza de las puntuaciones en los tests de CI que no se debe a g, corresponda a los factores de grupo o a la unicidad del test (algo que discutiremos más adelante). Un último ejemplo: Flynn escribió que “cuando eliminas g del rendimiento en el SAT, las puntuaciones todavía predicen las calificaciones (Coyle & Pillow, 2008)”. De nuevo, podemos apreciar una descripción adecuada, pero las palabras que suelen usarse no están. En este caso, no vemos “residuales”, que es lo que se discute en la referencia citada. Todo esto está bien, pero es importante traducir las palabras que usa Flynn a las que habitualmente usan los investigadores, tanto para mejorar la comprensión como por tradición.
Otro ejemplo: Flynn ha discutido extensamente que las ganancias no pueden atribuirse a g, como ha mostrado la mayor parte de la investigación sobre este aspecto de la inestabilidad de la puntuación [son muy escasos los resultados que han ido en la misma dirección. Para un ejemplo de resultado opuesto véase Colom, Juan-Espinosa, García, 2001. The secular increase in test scores is a 'Jensen effect’. Personality and Individual Differences, 30, 553-559]. Flynn ha optado por ignorar la posibilidad de que la varianza de las puntuaciones en los tests de CI que no se debe a g, corresponda a los factores de grupo o a la unicidad del test (algo que discutiremos más adelante). Un último ejemplo: Flynn escribió que “cuando eliminas g del rendimiento en el SAT, las puntuaciones todavía predicen las calificaciones (Coyle & Pillow, 2008)”. De nuevo, podemos apreciar una descripción adecuada, pero las palabras que suelen usarse no están. En este caso, no vemos “residuales”, que es lo que se discute en la referencia citada. Todo esto está bien, pero es importante traducir las palabras que usa Flynn a las que habitualmente usan los investigadores, tanto para mejorar la comprensión como por tradición.
Los
mecanismos que se proponen como causa del efecto Flynn se pueden organizar en
categorías y la siguiente es una opción:
-
Socio-ambientales (familia,
escuela, infraestructuras públicas, etc.).
-
Biológicas (nutrición, cuidados
sanitarios, genética/heterosis, etc.).
-
Relacionadas con los test
(familiaridad, adivinación, puntuación, etc.).
Socio-ambientales
A medida
que iba produciendo artículos y libros, la esencia del argumento de Flynn ha
ido cambiando desde la perspectiva de que “las ganancias deben ser un artefacto” a una
insistencia creciente en que las ganancias son reales, aunque no tengan
relación con g. Él y Dickens han propuesto que, en contraste
con lo sugerido por los estudios previos, la inteligencia puede estar gobernada
en mayor grado por el ambiente. Sugieren que los factores ambientales actúan
como multiplicadores sociales que
producen grandes efectos [Para los interesados en un estudio detallado sobre
los efectos ambientales, sugiero el capítulo 15 (de N. Brody) en H. Nyborg,
Editor, The Scientific Study of Human
Nature: a Tribute to Hans J. Eysenck at Eighty, Pergamon, Oxford (1997). El
excelente capítulo de Brody nos sorprendió a mi y a Nyborg. En resumen, Brody mostró
que los factores ambientales dan cuenta de una parte bastante reducida de las
diferencias de inteligencia].

El modelo de
Dickens-Flynn no se derivó inductivamente de los datos, sino que se construyó
para producir los resultados deseados. Tampoco se ha confirmado mediante
medidas. El movimiento de Flynn hacia la creencia aparente en la importancia de
las ganancias en el mundo real, ha ido parejo con su argumento sobre g. Ha evitado declaraciones sobre el
aumento de g y ha subrayado
que factores no relacionados con g
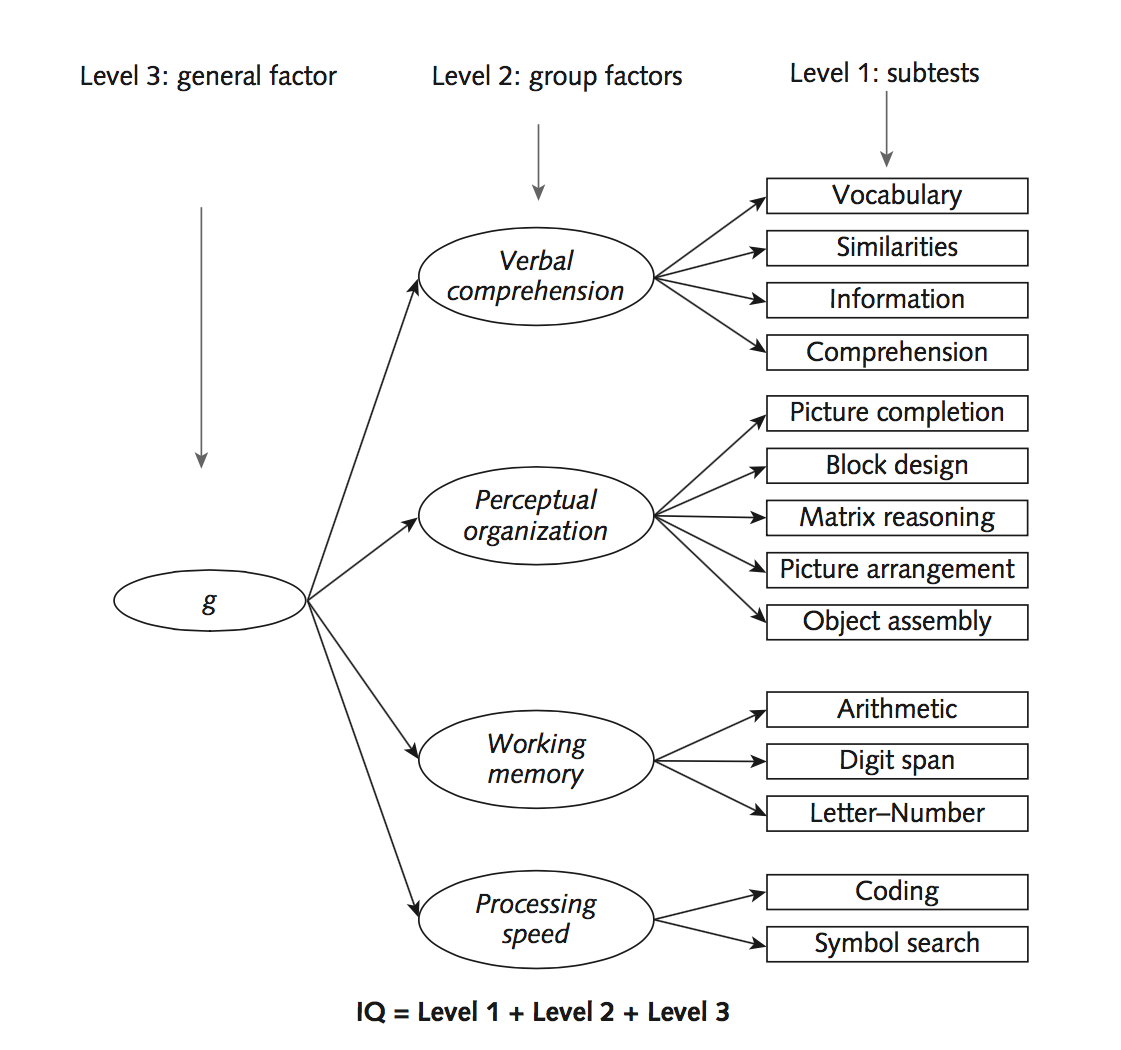
han aumentado y poseen consecuencias en ese mundo real. Los test de CI miden
varianza atribuible a g, capacidades
distintas de g (factores de grupo) y
unicidad (especificidad del test y error aleatorio). Solamente los factores de
grupo y la especificidad pueden representar capacidades distintas de g que contribuyan al rendimiento en los
test de CI. Por tanto, aquí tenemos un ejemplo de la desconexión lingüística
comentada anteriormente. Si las puntuaciones en los tests aumentan, sea cual sea
la causa debe corresponder a varianza de esos componentes. Por desgracia, Flynn
no usa los términos “factores de grupo” o “unicidad”, y, por tanto, debemos
suponer que describe una u otra (o ambas) fuentes de varianza. En el contexto
en el que se usa, asumo que los factores distintos de g son factores de grupo.
Según mi
perspectiva, parece que Flynn ahora cree que los factores ambientales causan
las ganancias en los factores de grupo que hacen que la gente sea
cognitivamente más capaz a través de las generaciones. Un problema de esta
línea de razonamiento es que se ha observado que los factores de grupo
(residuales de segundo estrato) de los test de CI apenas poseen validez externa
(de 0 a un 2%). Estos factores distintos de g
son reales, pero apenas poseen validez [Este es un resultado consistente en los
test de CI, pero Coyle & Pillow (citados por Flynn) han mostrado que, para
los test de logro académico, los residuales son casi tan predictivos del logro
académico como el factor g en esos
mismos test, mientras que los factores de grupo de los test de CI no presentan
esa capacidad predictiva]. Fui incapaz de encontrar una explicación en Flynn
sobre por qué los factores distintos de g
son relevantes respecto al aumento secular de las puntuaciones y los resultados
en el mundo real, cuando se ha observado consistentemente que carecen de
validez predictiva cuando se extraen de los test de CI. Otro problema del
argumento de que las ganancias poseen beneficios reales, es que no encaja con
el obvio carácter artificial de las ganancias debidas al Efecto Brand y a la
metodología del cálculo de puntuaciones que discutiremos después.
Biológicas
Richard
Lynn ha escrito mucho y en detalle sobre los cambios biológicos paralelos a las
ganancias seculares de CI [Lynn ha escrito un libro y varios artículos sobre la
presencia de un vector negativo (supuestamente con pesos en g) activo junto con las condiciones que
causan la ganancia secular de CI; este componente negativo se debe a la
fertilidad disgenésica y se ha visto supuestamente enmascarado por la presencia
del efecto Flynn. Otros investigadores han estudiado estas tendencias
disgenésicas, y puede encontrarse material particularmente interesante en H.
Nyborg, M. Woodley, y G. Meisenberg].
Las
siguientes variables han mostrado ganancias generacionales: tamaño craneal,
estatura, peso al nacer y maduración temprana. Flynn nunca ha cuestionado la
evidencia sobre cambios biológicos que puedan inspirar una conexión con las
ganancias de inteligencia, pero ha subrayado que las ganancias de estatura no
son contemporáneas a las ganancias de CI. Neisser
ha cuestionado los beneficios de las mejoras nutricionales y Mingroni ha argumentado que todos los
factores postnatales son implausibles debido a la alta consistencia de las
estimaciones de heredabilidad (la heredabilidad aumenta significativamente de
la infancia a la edad adulta –es decir, la tendencia opuesta a lo que cabe
esperar si los factores ambientales son relevantes).

Se han
discutido ampliamente varias medidas biológicas relacionadas con la
inteligencia. Medidas cronométricas como el tiempo de reacción (reaction
time, RT) y el tiempo de inspección
(inspection time, IT) han sido
estables durante largos periodos de tiempo, lo que sugiere que el factor g no está relacionado con los cambios
–en tal caso, los tiempos de reacción y de inspección deberían haberse reducido
(las generaciones recientes serían más rápidas). De hecho, se ha publicado una
serie de artículos conectados con los datos de Woodley que han mostrado que los tiempos de reacción han aumentado (las
generaciones recientes serían más lentas) desde la época de Galton [el resultado de este
interesante intercambio de artículos han sido ligeras modificaciones en los
números, pero la conclusión se ha mantenido].
Otro
parámetro biológico relacionado con la inteligencia es la capacidad de la memoria operativa (working memory capacity, WMC). Ha sido objeto de muchos artículos y
el estudio de su relación con la inteligencia fluida y con el factor g sigue siendo un activo campo de
investigación. Uno de los test más simples de memoria operativa, y sobre el que
hay datos históricos, es recuerdo inverso de números (backward digit recall). Los resultados han mostrado que las
puntuaciones en ese test no se han movido a lo largo de los años (puede que
incluso hayan disminuido). Por tanto, sea cual sea el papel de la memoria
operativa en el factor g, no se
observa cambio secular. Si existiese un cambio real de inteligencia, estos
correlatos biológicos deberían haberse modificado. Sin embargo, no ha sido así,
excepto por el leve declive en los tiempos de reacción (RT) observados por
Woodley.
Relacionados con los Test
Entre las
múltiples causas que se han propuesto sobre el cambio secular de CI, hay dos
bastante claras (con respecto a las bases de datos en cuestión) y ninguna
tiene nada que ver con las ganancias en las capacidades cognitivas. La primera
es el Efecto
Brand (nominado por Woodley). En 1996, Christopher Brand predijo que los evaluados de las generaciones más
recientes tendían a adivinar en mayor grado [Para una discusión sobre las
objeciones de Flynn a la observación inicial de Brand véanse las paginas 234-5
de la obra de Jensen ‘The g factor’,
1998]. Este efecto se demostró en una base de datos de Estonia en la que se
consideró un periodo de 72 años. Al comienzo de ese periodo, Estonia apenas manifestó
efecto Flynn, pero a medida que aumentó la importancia de los tests, los
estudiantes aprendieron que no se penalizaba las respuestas incorrectas, por lo
que comenzaron a adivinar con mayor frecuencia. Se observó que aumentaba el
número de ítems que intentaban responderse, lo que producía más respuestas tanto
incorrectas como correctas. Esto produjo no solamente un mayor efecto Flynn,
sino que, además, parecía que ganancias totalmente absurdas estaban
relacionadas con el factor g (esta es
la observación de Woodley: “la correlación entre las ganancias vía el Efecto Brand y los
pesos en g fue de .95, como se predijo”), porque la mayor parte de
la adivinación se concentraba en los ítems más difíciles, y, por tanto, con
mayores pesos en g. Esta categoría
general causal es consistente con la observación de Jensen de que las ganancias
del efecto Flynn son resultado, en parte, del aumento de la familiaridad con los
tests.

La segunda
causa relacionada con los test es la metodología para calcular las puntuaciones.
Beaujean & Osterlind examinaron
el National Longitudinal Survey of Youth
calculando puntuaciones con Teoría Clásica
(CTT) y con Teoría de Respuesta al Ítem (IRT).
Observaron que el efecto Flynn calculado para el Peabody Picture Vocabulary Test-Revised se desvanecía y que el
calculado para el Peabody Individual
Achievement Test-Math se reducía a la mitad. Este resultado no tiene nada
que ver con el cambio cognitivo, en igual medida que el Efecto Brand.
Los test de
CI se revisan periódicamente y vuelven a baremarse para corregir el efecto
Flynn. Si las ganancias tuvieran consecuencias reales, los nuevos baremos
ajustarían las puntuaciones medias a un valor menor del real, lo que provocaría
que los tests tendieran a predecir a la baja (infra-predecir) las medidas
criterio. Sin embargo, no he podido encontrar ningún informe en el que se haya observado
ese efecto. Flynn ha ignorado este hecho. Los test de CI son valiosos porque
poseen validez externa. Por tanto, creo que este simple aspecto de la deriva en
las puntuaciones, es central para la discusión de si las ganancias son
significativas. Si lo son, deberíamos considerar evitar la práctica de
re-baremar los test.
Volviendo a
las explicaciones de Flynn, existen argumentos muy plausibles que son
probablemente ciertos, hasta cierto punto. Pero esas explicaciones tienen
lagunas que resultan de ignorar artefactos que parecen un efecto Flynn y de
minimizar causas potenciales que no pueden descartarse de un plumazo. Cualquier
modelo sobre el efecto que merezca la pena debe explicar:
1.
Su presencia en niños de 1-2 años.
2.
La tendencia a que las ganancias se
detengan y luego se inviertan.
3.
Las ganancias conductuales reales (medidas)
observadas en las poblaciones, si se considera que las ganancias son
significativas.
4.
Los artefactos relacionados con los
test que no tienen nada que ver con la cognición.
Pensamientos Finales
Pienso que
la cuestión nuclear al examinar cualquier base de datos sobre el efecto Flynn, supone
reconocer que sea lo que sea que revele es específico del tiempo y lugar
considerado en esa base de datos. Y, por tanto, no puede extrapolarse
directamente a un tiempo y lugar diferente. Los argumentos ofrecidos por Flynn,
que yo considero como observaciones de ausencia de invarianza, me parecen robustos,
pero no son exclusivos de las numerosas condiciones que potencialmente pueden
producir ganancias o pérdidas en las puntuaciones.
No hay comentarios:
Publicar un comentario